
How to Use Python Regular Expressions
Regular expressions are a computer programming concept that allow you to search text for specific patterns.
Regular expressions are very useful. They can be used for tasks like:
- Password pattern matching, so users can't set their password to
password - Validating email formats
- Finding and replacing text in a document
This tutorial will teach you how to use regular expressions in Python.
Table of Contents
You can skip to a specific section of this Python regular expression tutorial using the table of contents below:
What are Regular Expressions?
Regular expressions or regex is a powerful programming feature that can be used for matching text patterns. The basic concept behind the regular expressions is that it provides the ability to specify a matching pattern using a special set of characters and the string to be matched. This allows us to transform the text according to our needs.
In Python, regular expression functionality is made available through the re module. The basic syntax for defining a regular expression is as follows:
re.<Regex Function>(<Pattern>,<String>, <Optional : flags>)Example Code
import re
search = re.search(r'String$', 'Hello World this is a String')
if search:
print(f"Match Found - {search.group()}")
print(search)
else:
print(f"Match Not Found")RESULT

In the above example, the search function in the re module is invoked and a regular expression is defined to check if the provided string ends with the word ‘String’. It will print the matching word and the search object which contains the information of the search and result if the condition becomes true.
When defining a pattern to be matched, it is always advisable to use the ‘r’ prefix as it will treat the preceding pattern as a raw string. Python raw strings consider the backslash () as a literal character. Therefore, we can mitigate any misidentifications of regex patterns by defining a regex pattern as a raw string.
Regex Patterns
When creating regular expressions, you can use special sets of characters and unique sequences to define patterns. These correlate to different functionalities that can be recognized by the regex engine and exchange the capability of searching. In the below section, you will find out the most commonly used metacharacters and sequences supported by the Python re module. For more information about this functionality, refer to the official Python documentation.
Metacharacters
| Character | Functionality |
|---|---|
| . (period) | Match any single character except newline |
| ^ | Match the start of a string |
| $ | Match the end of a string |
| \ | Escape special characters or denote character classes |
| * | Match zero or more repetitions |
| + | Match one or more repetitions |
| ? | Matches zero or one repetition |
| {} | Matches explicitly specified the number of repetitions |
| [] | Specifies a set of characters |
| | | Specifies OR |
| () | Create a group |
Special Sequences
| Character | Description |
|---|---|
| \w | Matches any alphanumeric character |
| \W | Matches any non-alphanumeric characters |
| \d | Matches any decimal digit |
| \D | Matches any non-digit character |
| \s | Matches any whitespace character |
| \S | Matches any non-whitespace character |
| \b | The boundary between word and non-word |
Python re Module
The re module offers a multitude of functionalities to perform regex actions. The regex functionality can be divided into two major categories,
- Search functions
- String Modification functions
The following sections will cover each category more precisely.
Search Functions
The search functions allow users to search for one or multiple matches in a string according to the specified regex. Python re module offers the following functions for searching.
| Function | Description |
|---|---|
| re.search() | Scans the complete string, searching for the defined regex. |
| re.match() | Looks for the matching regex at the beginning of the string. |
| re.findall() | Find all the substrings that match the regex pattern and return the matches as a list. |
| re.finditer() | Find all the substrings that match the regex pattern and return the matches as an iterator. |
re.search() Function
The search function will look for matches throughout the string for a certain regex pattern. It will return the matched object if a match is found or else it will return none.
import re
# Search Text
text = "Life is Beautiful"
print(re.search(r'Life', text))
# Search Text
text = "This is a Beautiful Life"
print(re.search(r'Life', text))
# Search for decimal digits
text = "value12345string"
print(re.search(r'\d+', text))
# Search for email address
text = "The user email is barry@gmail.com"
print(re.search(r'[\w]+@[\w.]+', text))RESULT

re.match() Function
The match function differs from the search function as it is only searching the beginning of a string for the matching regex pattern. The following examples demonstrate this behaviour.
import re
# Search Text
text = "Life is Beautiful"
print(re.match(r'Life', text))
# Search Text
text = "This is a Beautiful Life"
print(re.match(r'Life', text))
# Search for decimal digits
text = "value12345string"
print(re.match(r'\d+', text))
# Search for decimal digits
text = "12345valuestring"
print(re.match(r'\d+', text))
# Search for email address
text = "The user email is barry@gmail.com"
print(re.match(r'[\w]+@[\w.]+', text))
# Search for email address
text = "barry@gmail.com is the user email"
print(re.match(r'[\w]+@[\w.]+', text))RESULT
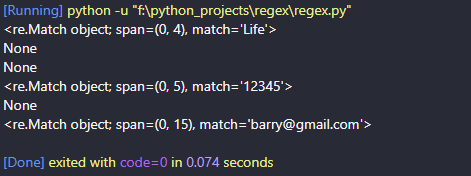
As you can see from the above examples, the matched instances are only located at the beginning of the matching string.
Multiline Strings
When dealing with a multiline string, you have to define the MULTILINE flag to match the regex pattern for each line. The MULTILINE flag will identify all the new lines that contain a string and perform the regex matching for each line separately.
import re
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.search(r'^World', multiline_string))
# MULTILINE Flag
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.search(r'^World', multiline_string, re.MULTILINE))
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.search(r'Beautiful$', multiline_string))
# MULTILINE Flag
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.search(r'Beautiful$', multiline_string, re.MULTILINE))RESULT

According to the above example, you can only match the defined regex patterns (a string starting with the word “World” [^] and a string ending with the word “Beautiful” [$]) when the MULTILINE flag is declared. The MULTILINE flag will only affect the “re.search()” function and not the “re.match()” function.
import re
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.match(r'^Hello', multiline_string))
# MULTILINE Flag
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.match(r'^World', multiline_string, re.MULTILINE))RESULT

The re.match() function will always be bound to the beginning of a string regardless of the multiline structure of the whole string. When you are searching for the word “World” (^World) in the above example, the second line starts with the given regex pattern but the result will be 'None' as the re.match() function only looks for the matching pattern at the beginning of the complete string.
re.findall() Function
The findall() function will return all non-overlapping matches of a specific regex pattern. It will search the string from left to right and return the matches in the order they were found.
import re
# Find all words
import re
# Find all words
string= 'hello---,,2134.world///3321$%^&python'
print(re.findall(r'[a-zA-Z]+', string))
# Find all alphanumeric characters
string= 'hello---,,2134.world///3321$%^&python'
print(re.findall(r'\w+', string))
# Find the word "World"
multiline_string = "Hello\nWorld is Beautiful\nIts a Mysterious World"
print(re.findall(r'World', multiline_string, re.MULTILINE))
# Get each item in the list
string= 'hello---,,2134.world///3321$%^&python'
item_list = re.findall(r'[a-zA-Z]+', string)
item_num = 0
print(f'\nItem List')
for x in item_list:
item_num += 1
print(f'Item {item_num} = {x}')RESULT

re.finditer()
The finditer() function will find all the non-overlapping matches of a specific regex pattern and return an iterable object with all matched items as a match object. This function also searches the string from left to right and returns the matching items in the order they were found.
import re
# Find all words
string= 'hello---,,2134.world///3321$%^&python'
iterable_object = re.finditer(r'[a-zA-Z]+', string)
for x in iterable_object:
print(x)
print('')
# Find all alphanumeric characters
string= 'hello---,,2134.world///3321$%^&python'
iterable_object = re.finditer(r'\w+', string)
for x in iterable_object:
print(x)RESULT

re.findall() vs re.finditer()
Both these functions are similar in functionality, returning all the matching items of a provided string. However, there are two key differences;
| re.findall() | re.finditer() |
|---|---|
| Returns a list of all the matching items. | Returns an iterable object of all the matching items. |
| Items in the list are matched strings. | The iterable object consists of matched items as match objects. |
Each function can be used interchangeably. One of the advantages of re.finditer() function is that the match object provides more information regarding the matched item.
Match Object
In most cases, the re module will return a match object for a regex match. A match object contains multiple pieces of information regarding the matched item. Following is a list of commonly used methods that are available for a match object.
| Method | Description |
|---|---|
| match.group() | Return the specified group or groups from the match. |
| match.groups() | Get all the captured groups. |
| match.groupdict() | Get a dictionary of captured groups. |
| match.start() | Starting index of the match |
| match.end() | Ending index of the match |
| match.span() | Starting and Ending index as a tuple |
In the below section, we will go through each of the above-mentioned methods.
match.group() Method
This method will return the specified group of the matched object. The group() method supports both named and unnamed regex groups. If the specified index of the group is out of the range or nonexistent, Python will raise an IndexError.
Unnamed group
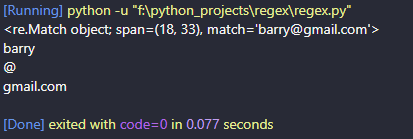
import re
text = "The user email is barry@gmail.com"
result = re.search(r'(\w+)(@)(\w.+)', text)
print(result)
print(result.group(1))
print(result.group(2))
print(result.group(3))RESULT
Named group
A named group can be created using the following syntax: (?P
Let's have a look at how you can create a named group and retrieve the named group via the group method.
import re
text = "The user email is barry@gmail.com"
# Named Groups
result = re.search(r'(?P<part1>\w+)(?P<symbol>@)(?P<part2>\w.+)', text)
print(result)
# Define the Group Name
print(result.group('part1'))
print(result.group('symbol'))
print(result.group('part2'))RESULT

Multiple arguments
It is possible to define multiple arguments within the group method which will return a tuple containing all the defined groups. Multiple arguments are supported by both named and unnamed groups.
import re
text = "The user email is barry@gmail.com"
# Named Groups
result = re.search(r'(?P<part1>\w+)(?P<symbol>@)(?P<part2>\w.+)', text)
print(result)
# Multiple Groups
print(result.group('part1', 'part2'))
# Unnamed Groups
text = "This is a Fantasy World"
result = re.match(r'(\w+)\s(\w+)\s(\w+)\s(\w+)', text)
print(f"\n{result}")
# Multiple Groups
print(result.group(2, 3, 4))
print(result.group(1, 2))RESULT

match.groups() Method
The groups() method will return a tuple of all the captured groups.
import re
text = "This is a Fantasy World"
result = re.search(r'(\w+)\s(\w+)\s(\w+)\s(\w+)', text)
print({result})
print(result.groups())RESULT

match.groupdict() Methods
This method will return a dictionary of captured groups and only work with named groups.
import re
text = "This is a Fantasy World"
result = re.search(r'(?P<val1>\w+)\s(?P<val2>\w+)\s(?P<val3>\w+)', text)
print({result})
print(result.groupdict())
# Print each key value pair in the Dictionary
for key in result.groupdict():
print(f"{key} = {result.groupdict()[key]}")RESULT

match.start() and match.end() Methods
These two methods obtain the starting index and the ending index of a specific regex pattern match.
import re
text = "---&&*Hello8347World%##@"
result = re.search(r'[a-zA-z]+', text)
print(result)
# Starting Index
print(result.start())
# Ending Index
print(result.end())
text = "---&&*Hello///8347World%##@"
result = re.search(r'([a-zA-z]+)\W*\d+(?P<val2>\w+)', text)
print(f"\nresult")
print(result.group(1))
print(f"\nStarting Index = {result.start(1)}\nEnding Index = {result.end(1)}")
print(result.group('val2'))
print(f"\nStarting Index = {result.start('val2')}\nEnding Index = {result.end('val2')}")RESULT

match.span() Method
This method Returns both the starting and ending index values of the regex match. This method also supports both named and unnamed groups.
import re
text = "---&&*Hello8347World%##@"
result = re.search(r'[a-zA-z]+', text)
print(result)
# Print the Span
print(result.span())RESULT

String Modification Functions
The regex string modification functions allow users to replace the matching regex pattern with a specified string and to split strings according to a certain regex. Following are the widely used string modification functions within the re module.
| Function | Description |
|---|---|
| re.sub() | Scans a string and replace the matching regex pattern with the given replacement string |
| re.subn() | The same function as the sub() function but provides additional information about the number of substitutions made. |
| re.split() | Splits a string into substrings using the regex (The regex pattern will be used as a delimiter) |
re.sub() Function
The sub() method will replace the non-overlapping, matching regex patterns starting from left to right. This will create a new string while keeping the original string untouched. If the method does not find any matches, it will return the original string. As Python strings are immutable objects, the result of substitutions will always be a new string.
The sub() method syntax can be declared as follows.
re.sub(<Regex>, <Replacement>, <String>, <Optional : count>, <Optional : flags>)The below examples will provide you with an understanding on how to use substitutions.
Simple Substitution
import re
text = "Hello---World---,---Today--is--a--New------Day"
# Replace the dashes with a space
new_string = re.sub(r'\W+', ' ', text)
print(new_string)
# Replace 0000 with ---
text = "Hello---World---,0000Today00is00a00New00Day"
new_string = re.sub(r'\d+', '---', text)
print(new_string)RESULT

Limiting Substitutions
The optional parameter “count” allows you to limit the number of replacements.
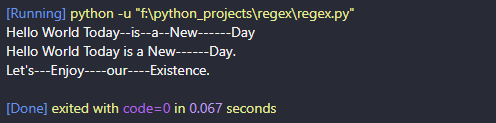
import re
text = "Hello---World---,---Today--is--a--New------Day"
# Replace the dashes with a space only 2 times
new_string = re.sub(r'\W+', ' ', text, count=2)
print(new_string)
# Multiline String
text = "Hello@@@World===.\n---Today--is--a--New------Day. \
\nLet's---Enjoy----our----Existence."
# Replace any non alphanumeric character sets 5 times in a Multiline String
# The flag re.M is used to indicate a multiline string
new_string = re.sub(r'\W+', ' ', text, count=5, flags=re.M)
print(new_string)RESULT
re.subn() Function
The Python subn() method acts similar to the sub() method, replacing matching items for a specific regex while also returning the number of replacements.
import re
text = "Hello@@@World===---Today--is--a--New------Day."
# Replace all non alphanumeric characters
new_string = re.subn(r'\W+', ' ', text)
print(new_string)RESULT

re.split() Function
The split() function will split a specific string by using the regex as the delimiter. The optional “maxsplit” flag allows the user to determine the number of times the string will be split. The split() function can be declared as follows,
re.split(<Regex>, <String>, <Optional: Flags>)The below example shows us how we can split strings using regex patterns.
import re
text = "Hello@@@World@This@@is@@a---Computer"
# Split by any non alphanumeric character
print(re.split(r'\W+', text))
# Print matching delimiters
print()
print(re.split(r'(\W+)', text))
# maxsplit value
print()
print(re.split(r'\W+', text, maxsplit=2))RESULT

Final Thoughts
In this article, you were presented with a basic overview of regular expressions. What regular expressions are and how they can be used with Python to perform string manipulations. Regular expressions are a powerful tool in any programming context, providing developers with a precise method to carry out string searches, substitutions, separations, etc... ranging from simple to complex regex patterns.