
So far in our discussion in convolutional neural networks, you've had a broad overview of CNNs as well as an explanation of the role of convolutions in these neural networks.
Next up, we will discuss the ReLU layer and the role of pooling in convolutional neural networks
Table of Contents
You can skip to a specific section of this Python deep learning tutorial using the table of contents below:
- The ReLU Layer
- Pooling in Convolutional Neural Networks
- Visualizing the Pooling Layer
- Final Thoughts
The ReLU Layer
In our last tutorial, we stopped at the point where we had generated multiple feature maps that used different feature detectors.
What happens next?
The feature maps are passed into an activation function - just like they would be in a normal artificial neural network. More specifically, they are passed into a rectifier function, which returns 0 if the input value is less than 0 and it returns the input value otherwise.
Here is a visual representation of this ReLU layer:
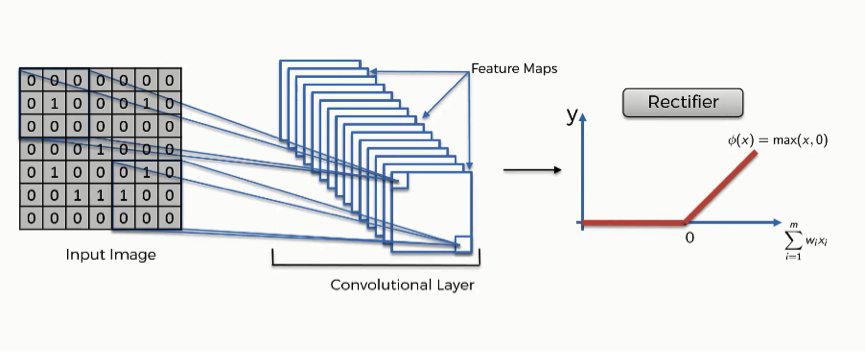
The reason why the rectifier function is typically used as the activation function in a convolutional neural network is to increase the nonlinearity of the data set. You can think of this as the desire for an image to be as close to gray-and-white as possible. By removing negative values from the neurons' input signals, the rectifier function is effectively removing black pixels from the image and replacing them with gray pixels.
Pooling in Convolutional Neural Networks
Now that the rectifier function has removed black pixels from our image, it's time to implement some maximum pooling techniques.
The purpose of max pooling it to teach the convolutional neural networks to detect features in an image when the feature is presented in any manner. A few examples of this are below:
- Recognizing cats when they are standing or laying down
- Recognizing eyes regardless of their eye color
- Recognizing a face whether it is smiling or growing
- Recognizing animals whether they are close or in the distance
To make this work, the convolutional neural network must be taught a property called spatial variance.
pooling is the process that allows us to introduce spatial variance. There are numerous types of pooling (including sum pooling and mean pooling) but we will be working with max pooling in this tutorial.
Pooling is used to transform a feature map into a pooled feature map, which is smaller and is calculated based on the original feature map using a similar matrix overlay technique as the convolutions we learned about earlier in this course.
Let's consider an example that transforms a 5x5 feature map into a pooled feature map of dimensions 3x3 using max pooling. We'll do this using a 2x2 overlay box.
To start, place your 2x2 overlay box in the top-left corner of the feature map. Take the largest value contained in the matrix overlay - this becomes the first value in the pooled feature map. Now move the box by the amount of your stride. Continue this process until the pooled feature map is full.
Note that depending on the value of your stride, you may move part of your overlay box off of your feature map, like this:
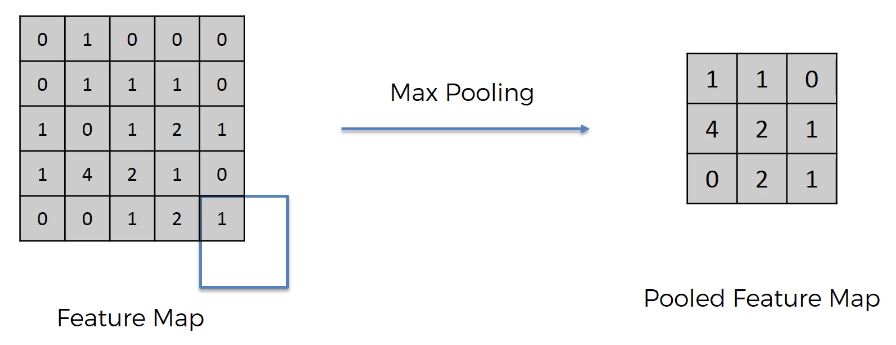
Pooling is beneficial because it reduces the dimensionality of the data we're training on, which lowers the chance that our model will be overfitted on our training data.
Visualizing the Pooling Layer
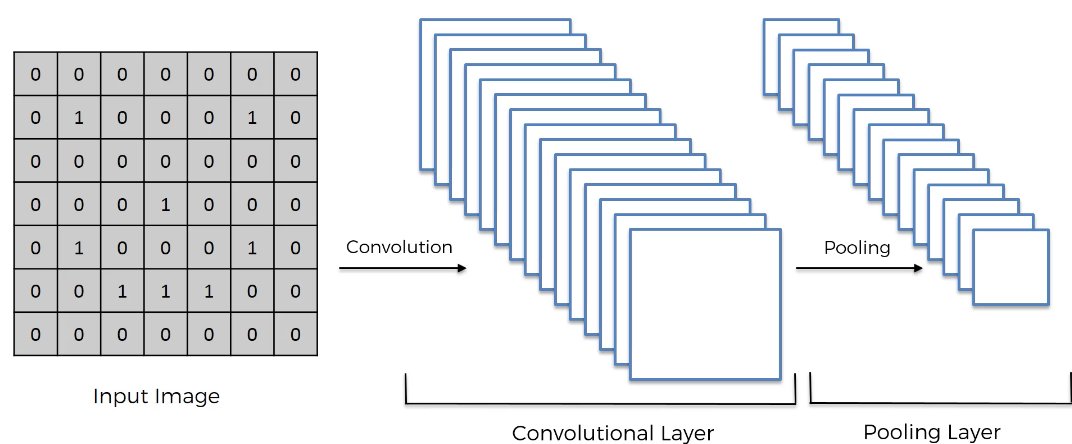
Now that our pooling step has been completed, here is a visual representation of all the steps we've completed:
Final Thoughts
In this tutorial, you learned about the ReLU layer and the pooling process within convolutional neural networks.
Here is a brief summary of what you learned in this tutorial:
- That data is passed from a feature map through the ReLU layer in a convolutional neural network
- That the purpose of the ReLU layer is to improve the nonlinearity of the image's pixel data
- That pooling is used to inject
spatial varianceinto a convolutional neural network - How pooling is similar to creating a feature map in that they both use matrix overlay techniques