
How to Create a Beautiful Soup Web Scraper in Python
The internet is brimming with data about any topic you can imagine.
Much of this data exists on websites on public domains that you can access through a web browser. To harness this data, you'll need to learn the valuable skill of Python web scraping.
This tutorial will teach you about the basics of web scraping by using a practical example. More specifically, we'll scrape job postings from the PythonJobs website using Python's BeautifulSoup library.
Table of Contents
You can skip to a specific section of this Python web scraping tutorial using the table of contents below:
Why Use Web Scraping?
Imagine you're looking for a new job.
This job has to be related to software development and has to be in New York City. Since the odds of you finding your dream job on day one of your search are slim, you'll probably have to invest a serious amount of time to search for a new job.
Manually searching for a job is very time consuming. It's also boring and tiring...
You can automate this part of your job hunt by creating a custom web scraper using BeautifulSoup. The script will scrape the data from your favorite job listing website and save them to a file on your local machine.
Automated web scraping will speed up your data collection process, increase your reach to new jobs, and save you time, allowing you to spend your time on things that are more important.
Web scraping also allows you to be much more thorough. Data is almost constantly added to every website on the Internet. It's impossible to keep track of all of this data without software.
According to the World Economic Forum, by 2025, 463 exabytes of data will be created each day globally.
1 exabyte is equal to 1 billion gigabytes.
This scale is insane... For context, a good movie has a file size of 1 to 2 GB. This demonstrates the size of the internet and how inefficient it is to manually skim through the internet to look for a new job.
The Challenges of Web Scraping
Building websites is complicated.
It involves the use of multiple technologies that work together to provide a seamless user experience. Websites are also constantly changing and growing. This leads to a few challenges when you’re trying to build automated scripts to scrape websites.
The main challenge of building a web scraper is the variety of websites designs that are available today. Websites do not follow a specific template. Despite having a general structure, each website is unique. Because of this, each website requires a customized scraper that deals with the extraction of the required information.
The other main challenge of Python web scraping is change. Websites are constantly changing. They often add new features or update old ones. What this means for a web scraper is that the code you write today may not function properly in the future.
However, the changes are mostly incremental. This means it usually isn't too difficult to update your scraper to work with the website's new design.
What are APIs
Application Programming Interfaces (API) are the alternative to web scraping. APIs allow some websites to provide you with programmatic access to their data. As an example, here are a few companies that expose their data sets (for free!) through APIs:
APIs tend to simplify the work of scraping data and make its retrieval more consistent by providing a method that you can use to extract data.
APIs are more reliable than web scraping because they are immune to being broken by visual updates on the website. Said differently, an update on the website does not mean that the structure of the data exposed through the API has been changed.
APIs also allow you to avoid parsing complex HTML and get results in the form of an easy-to-digest JSON or XML file.
This does not mean that APIs do not change. If the structure of the data changes or the data provider is releasing a new feature then they may change the API data structure. Because of this, working with APIs can be a challenge without proper documentation.
You should check whether the website or the service you are trying to scrape provides an API before building a Python web scraper. If an API exists, you should always use it instead of building your own web scraper.
Teaching APIs is out of this tutorial’s domain, but understanding how they work is important for avoiding unecessary work.
Let’s move on to how you can scrape information from the feed of PythonJobs.
Scraping from PythonJobs
In this tutorial, we'll build a web scraper using Python and the BeautifulSoup Python library to extract listings from PythonJobs. The web scraper will parse the extracted HTML from PythonJobs to gather relevant information filtered using specific words.
Using the technique that will be used in this tutorial, you can scrape any static website on the Internet.
Getting Ready
Before getting started with parsing, you need to install the relevant Python packages.
There are two packages that you'll require to scrape websites: requests and BeautifulSoup. The requests package helps you retrieve HTML from a provided URL. BeautifulSoup helps in parsing the HTML to extract meaningful information.
You can install requests with the following command:
PS C:\Users\Python\pythonJobs> pip install requestsSimilarly, you can install BeautifulSoup with the following statement:
PS C:\Users\Python\pythonJobs> pip install beautifulsoup4Now that the necessary packages are installed, you can start the process of parsing websites using Python.
Getting the HTML
The first step in scraping websites is getting the raw HTML data from the relevant website.
This tutorial is focused on scraping from PythonJobs. The following code gets the HTML from the website and writes it to an html.txt file.
import requests
URL = 'https://pythonjobs.github.io/'
page = requests.get(URL)
htmlfile = open('html.txt','w+')
htmlfile.write(str(page.content))
htmlfile.close()You can view the extracted HTML by opening the html.txt file. The text file will be hard to read since it contains all of the HTML (including all of its extra tags and data), not just the page's text.
Knowing What to Extract
Before starting on the parsing process, you need to understand the structure of the HTML you are working with.
Said differently, you need to know what to parse and which tags hold the information that you need.
The following HTML has been extracted from the PythonJobs website. It describes the structure of one job posting.
<div class="job" data-order="3" data-slug="ecs_python_developer_london" data-tags="python,aws,lambda,connect,typescript,react,s3,kenesis">
<a class="go_button" href="/jobs/ecs_python_developer_london.html"> Read more <i class="i-right"></i> </a>
<h1><a href="/jobs/ecs_python_developer_london.html">Senior Python Developer</a></h1>
<span class="info"><i class="i-globe"></i> Bermondsey, London, England</span>
<span class="info"><i class="i-calendar"></i> Fri, 30 Aug 2019</span>
<span class="info"><i class="i-chair"></i> permanent</span>
<span class="info"><i class="i-company"></i> ECS Digital</span>
<p class="detail">
Python Developer ECS is looking for experienced Python developers to join a project which will deliver telephony based on Amazon's Connect platform. We are building the next generation of contact centre based on AWS...
</p>
<div class="search_match"></div>
</div>You can read the HTML directly from the website with the help of developer tools, which can be accessed by pressing F12 (if you’re using Google Chrome browser).
The HTML may be unstructured when accessed using developer tools. You can use an HTML Formatter to format the HTML into nicely structured code.
For this tutorial, we will be focused on retrieving jobs for Python developers available in the UK. Reading the HTML, it is evident that the main <div> with a class “job” and the word “python” in the attribute of data-tags correspond to a job of a Python developer.
Now that the condition for a Python job has been determined, you can figure out how to determine the location of the employer.
From the HTML, you can see that the <span> with the child <i> that has class i-globe contains the location of the job. You can extract the text and match it using string comparison.
Now that the conditions have been defined, let’s translate all of this into code by using the BeautifulSoup package.
Extraction using BeautifulSoup
BeautifulSoup is a well-documented package that makes it really easy to scrape websites in Python. Extending the Python code defined earlier, we can use BeautifulSoup to parse the extracted HTML.
import requests
from bs4 import BeautifulSoup
URL = 'https://pythonjobs.github.io/'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
pythonJobs = soup.select('div[data-tags*="python"][class="job"]')
for job in pythonJobs:
print(job.prettify())Let's work through this code step-by-step.
First, the BeautifulSoup package is imported.
Next a soup object is created that reads the HTML extracted from the PythonJobs. A parser has to be defined with every BeautifulSoup object.
We pass in html.parser as the second argument to do this (the alternative would be the xml.parser argument since BeautifulSoup also works well with xml files).
Using the soup object, all the <div> tags having a class of job and containing the word “python” in their attribute data-tags are selected via CSS selectors. These tags are stored in the pythonJobs variable.
Next, the pythonJobs object is iterated one by one and each job inside pythonJobs is printed. The method prettify() formats the HTML to make it easier for a human to read.
Running the code will print out all the Python-related job postings from the PythonJobs website. Now let’s filter them based on their locations and store them in a text file.
To filter the jobs based on their location let’s extract the <i> tag with the class i-globe and then get its parents. You can easily check if the job is in the UK by comparing the text to an array of strings that match the UK, like this:
for job in pythonJobs:
iGlobe = job.find("i", class_="i-globe")
location = iGlobe.parent
locationText = location.get_text().upper()
matches = ['UK','ENGLAND','U.K.']
if any(match in locationText for match in matches):
print(locationText)Now that it is verified that each job meets our location criteria, you can extract the required information using an if statement:
if any(match in locationText for match in matches):
title = job.select_one('h1 > a')
titleText = title.get_text()
datePosted = job.find("i", class_="i-calendar")
datePosted = datePosted.parent
datePostedText = datePosted.get_text()
company = job.find("i", class_="i-company")
company = company.parent
companyText = company.get_text()
description = job.find("p", class_="detail")You can find the title, the date at which the job was posted, the name of the company, and the job description. You can also store all this information in a structured manner in a text file.
Here's the code to do this:
jobFile = open("jobs.txt", 'a+')
jobFile.write("Title: "+titleText+"\n Date: "+datePostedText+"\n Company: "+companyText+"\n Job Description: "+description.get_text()+"\n\n\n")This should produce the text file shown below:
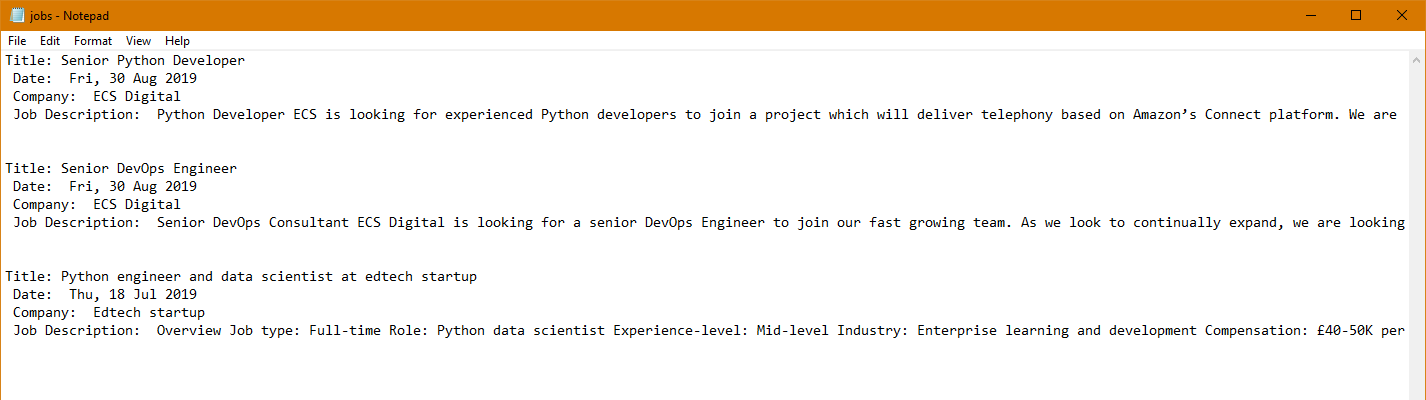
Just like that, you've built your first Python web scraper!
Final Thoughts
Python web scraping is not as simple as it sounds. With the help of packages like BeautifulSoup, you can do a lot of cool things. This tutorial taught you the basics of Python web scraping using BeautifulSoup.
This tutorial was introductory in nature and barely scratched the surface of BeautifulSoup's capabilities. Read their documentation to learn what more about its features.
BeautifulSoup fulfills most modern Python web scraping requirements and due to its comprehensive documentation and robust community, it is the undisputed leader in the Python web scraping space.