
In this lesson, we will begin exploring data input and output with the pandas Python library.
The File We Will Be Working With In This Lesson
We will be working with different files containing stock prices for Facebook (FB), Amazon (AMZN), Google (GOOG), and Microsoft (MSFT) in this lesson. To download these files, download the entire GitHub repository for this course here. The files used in this lesson can be found in the stock_prices folder of the repository.
You'll want to save these files in the same directory as your Jupyter Notebook for this lesson. The easiest way to do this is to download the GitHub repository, and then open your Jupyter Notebook in the stock_prices folder of the repository.
How To Import .csv Files Using Pandas
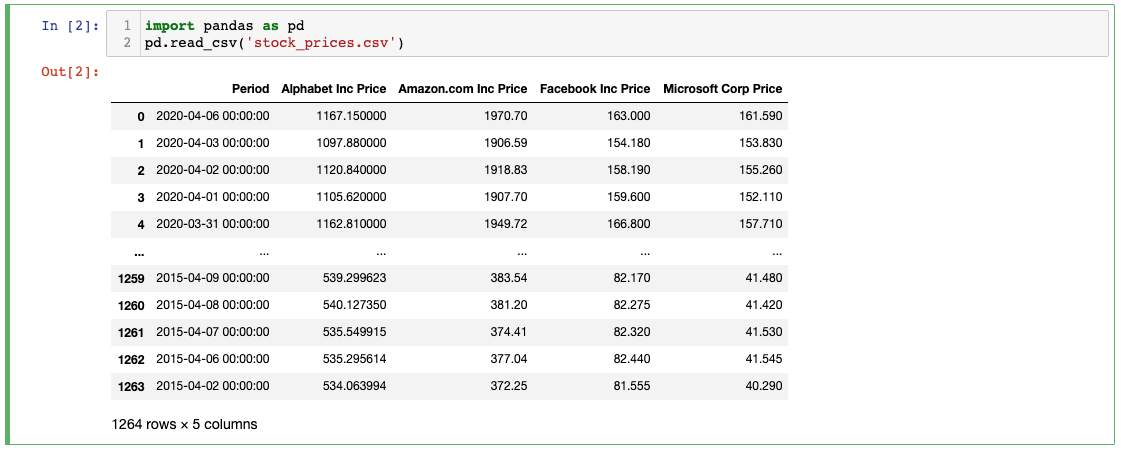
We can import .csv files into a pandas DataFrame using the read_csv method, like this:
import pandas as pd
pd.read_csv('stock_prices.csv')As you'll see, this creates (and displays) a new pandas DataFrame containing the data from the .csv file.
You can also assign this new DataFrame to a variable to be referenced later using the normal = assignment operator:
new_data_frame = pd.read_csv('stock_prices.csv')There are a number of read methods included with the pandas programming library. If you are trying to import data from an external document, then it is likely that pandas has a built-in method for this.
A few examples of different read methods are below:
pd.read_json()
pd.read_html()
pd.read_excel()We will explore some of these methods later in this lesson.
If we wanted to import a .csv file that was not directly in our working directory, we need to modify the syntax of the read_csv method slightly.
If the file is in a folder deeper than what you're working in now, you need to specify the full path of the file in the read_csv method argument. As an example, if the stock_prices.csv file was contained in a folder called new_folder, then we could import it like this:
new_data_frame = pd.read_csv('./new_folder/stock_prices.csv')For those unfamiliar with working with directory notation, the . at the start of the filepath indicates the current directory. Similarly, a .. indicates one directory above the current directory, and a ...indicates two directories above the current directory.
This syntax (using periods) is exactly how we reference (and import) files that are above our current working directory. As an example, open a Jupyter Notebook inside the new_folder folder, and place stock_prices.csv in the parent folder. With this file layout, you could import the stock_prices.csv file using the following command:
new_data_frame = pd.read_csv('../stock_prices.csv')Note that this directory syntax is the same for all types of file imports, so we will not be revisiting how to import files from different directories when we explore different import methods later in this course.
How To Export .csv Files Using Pandas
To demonstrate how to save a new .csv file, let's first create a new DataFrame. Specifically, let's fill a DataFrame with 3 columns and 50 rows with random data using the np.random.randn method:
import pandas as pd
import numpy as np
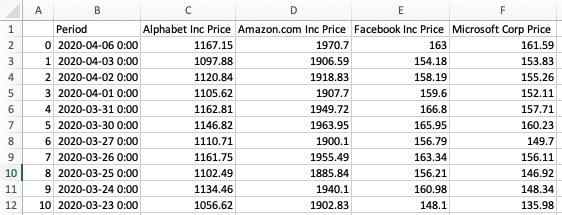
df = pd.DataFrame(np.random.randn(50,3))Now that we have a DataFrame, we can save it using the to_csv method. This method takes in the name of the new file as its argument.
df.to_csv('my_new_csv.csv')You will notice that if you run the code above, the new .csv file will begin with an unlabeled column that contains the index of the DataFrame. An example is below (after opening the .csv in Microsoft Excel):
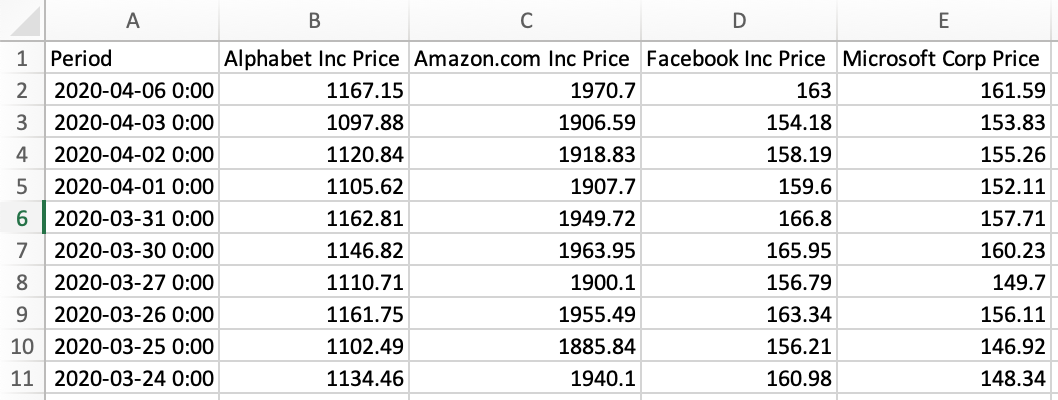
In many cases, this is undesirable. To remove the blank index column, pass in index=False as a second argument to the to_csv method, like this:
new_data_frame.to_csv('my_new_csv.csv', index = False)The new .csv file does not have the unlabelled index column:
The read_csv and to_csv methods make it very easy to import and export data from .csv files using pandas. We will see later in this lesson that for every read method that allows us to import data, there is usually a corresponding to function that allows us to save that data!
How To Import .json Files Using Pandas
If you are not experienced in working with large datasets, then you may not be familiar with the JSON file type.
JSON stands for JavaScript Object Notation. JSON files are very similar to Python Dictionaries.
JSON files are one of the most commonly-used data types among software developers because they can be manipulated using basically every programming language.
Pandas has a method called read_json that makes it very easy to import JSON files as a pandas DataFrame. An example is below.
json_data_frame = pd.read_json('stock_prices.json')We'll learn how to export JSON files next.
How To Export .json Files Using Pandas
As I mentioned earlier, there is generally a to method for every read method. This means that we can save a DataFrame to a JSON file using the to_json method.
As an example, let's take the randomly-generated DataFrame df from earlier in this lesson and save it as a JSON file in our local directory:
df.to_json('my_new_json.json')We'll learn how to work with Excel files - which have the file extension .xlsx - next.
How To Import .xlsx Files Using Pandas
Pandas' read_excel method makes it very easy to import data from an Excel document into a pandas DataFrame:
new_data_frame = pd.read_excel('stock_prices.xlsx')Unlike the read_csv and read_json methods that we explored earlier in this lesson, the read_excel method can accept a second argument. The reason why read_excel accepts multiple arguments is that Excel spreadsheets can contain multiple sheets. The second argument specifies which sheet you are trying to import and is called sheet_name.
As an example, if our stock_prices had a second sheet called Sheet2, you would import that sheet to a pandas DataFrame like this:
new_data_frame.to_excel('stock_prices.xlsx', sheet_name='Sheet2')If you do not specify any value for sheet_name, then read_excel will import the first sheet of the Excel spreadsheet by default.
While importing Excel documents, it is very important to note that pandas only imports data. It cannot import other Excel capabilities like formatting, formulas, or macros. Trying to import data from an Excel document that has these features may cause pandas to crash.
How To Export .xlsx Files Using Pandas
Exporting Excel files is very similar to importing Excel files, except we use to_excel instead of read_excel. An example is below using our randomly-generated df DataFrame:
df.to_excel('my_new_excel_file.xlsx')Like read_excel, to_excel accepts a second argument called sheet_name that allows you to specify the name of the sheet that you're saving. For example, we could have named the sheet of the new .xlsx file My New Sheet! by passing it into the to_excel method like this:
df.to_excel('my_new_excel_file.xlsx', sheet_name='My New Sheet!')If you do not specify a value for sheet_name, then the sheet will be named Sheet1 by default (just like when you create a new Excel document using the actual application).
Moving On
In this lesson, we had our first experience working with data input and output using the pandas Python library. After working through some practice problems, we will learn how to import data when it is not in our local directory, which is a very common situation in software development.